
Payments Systems that Scale
16 year fintech veteran explains how to build payments systems that scale.
Watch WebinarRunning a geographically distributed database has a lot of benefits. We see enterprise companies, startups, and students choose distributed databases for reliability, scalability, and even security. But many distributed databases come at a serious cost: latency. Distributing nodes across the globe means your data will need to travel from one node to the other. By its very definition, distribution creates latency.
Geo-partitioning your data in CockroachDB makes it easy to minimize that latency. We believe you shouldn’t have to sacrifice the benefits of a distributed database to achieve impressive throughput and low latency. With geo-partitioning, we can minimize latency by minimizing the distance between where SQL queries are issued and where the data to satisfy those queries resides.
In a recent episode of The Cockroach Hour, CockroachDB experts walked viewers through this exact dilemma, and reduced a 9-node geo-distributed CockroachDB cluster from experiencing 400ms of latency to well under 10ms (in real time). In today’s blog post, we’ll walk through the demo, and the mechanics that made the latency reduction possible.
Understanding Database Latency
When examining your application latency (in CockroachDB and other analytic platforms) you’ll see two important terms:
What is P99 latency?
P99 latency is the 99th latency percentile. This means 99% of requests will be faster than the given latency number. Put differently, only 1% of the requests will be slower than your P99 latency.
What is 90 latency?
The 90th latency percentile. This time, 90% of requests will be faster than the given latency number, and 10% of the requests are allowed to be slower than your P99 latency.
Providing a low latency experience for users fosters retention, encourages continued engagement, and most importantly, increases conversions. The question becomes, what are my target P99 and P90 latencies?
This is highly dependent on what kind of application you’re running–and what the user expectations are–but there’s one important thing to keep in mind: the 100ms Rule.
What is the 100ms rule?
The 100ms rule states that every interaction should be faster than 100ms. Why? 100ms is the threshold where interactions feel instantaneous.
The 100ms Rule was coined by Gmail developer Paul Buchheit. It isn’t hard if you have a single-region application with nearby users. But as mentioned, distributed databases often pay a latency toll in order to get benefits like high availability and resilience. That’s where geo-partitioning comes into play.
Another important factor to note, when examining latency: there are lots of different types of latency, each with their respective impacts on performance. Database latency can be a big part of that, but you’ll also need to look into your asset download time, data processing time, and initial loading time to get a full picture, like the one below:
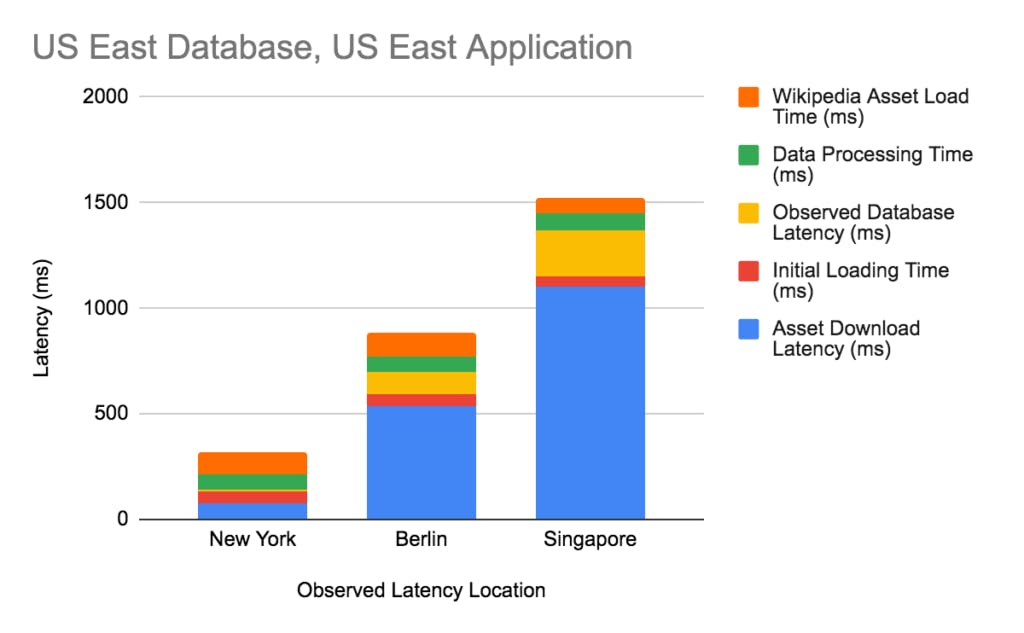
In our blog post Reducing Multi-Region Latency with Follower Reads, we go into great detail about how to use Uptrend’s free website speed test to break down where your latency is coming from.
What is geo-partitioning?
Geo-partitioning is the ability to control the location of data at the row level. By default, CockroachDB lets you control which tables are replicated to which nodes. But with geo-partitioning, you can control which nodes house data with row-level granularity. This allows you to keep customer data close to the user, which reduces the distance it needs to travel, thereby reducing latency and improving user experience.
How Geo-Partitioning Data Reduces Latency
When your application is running across multiple regions, and you have customers all over the world, it’s important to think about where your data lives. If a user in California is requesting something from Europe, you need to account for the time it takes to wire the data across the globe. Geo-partitioning data lets you mitigate that.
In the demo below, CockroachDB expert Keith McClellan runs our sample app, MovR, to illustrate a 9-node cluster distributed across the United States, with users in New York, LA, and Chicago. He applies geo-partitioning rules to build secondary indexes in his database. This is all done during an online schema change–he’s re-distributing data while the cluster is still live. The change moves records to be primarily domiciled in the right regions, and optimizes range partitions to make it easier to make changes further downstream.
The initial result: P99 latency drops from 400ms to well under 40ms. It’s a 10x improvement, and, more importantly, well under the 100ms rule.
Later in the demo, Keith goes even further, partitioning indexes such that the P99 latency is reduced to around 2ms. He identifies one table that’s used in all geographies: the promo codes table. It’s reference data that will be used by the app’s customers whether they’re in US east, central, or west. Keith wants it to be locally, consistently available, and not have to reach across regions for the authority to act on that data.
The solution: create some partitioned indexes that allow us to respond from the local replica of the data, while still guaranteeing consistency. P99 latency goes down even further because now–for the promo code reference data–all three locations have local access to that data.
To run Keith’s tutorial yourself, check out our docs on the subject, which contain the sample code.
How CockroachDB Reduces Latency with Geo-partitioning
CockroachDB is a distributed OLTP engine that, like many distributed systems, stores data across many nodes. But CockroachDB is the only distributed database to take this one step further: you have control of where data lives. As your cluster grows, and you begin to have nodes contributing from all across the world, it becomes increasingly important (and advantageous) to take advantage of that control.
To see real-world examples of geo-partitioning in action, you can read about how an electronic lock manufacturer is using the Geo-Partitioned Replicas topology in production for improved performance and regulatory compliance.


